3.4 从 C10K 到 C10M
Linux 内核是性能瓶颈所在
从前面内核网络优化的章节描述中,可以总结出 Linux 内核网络协议栈为基础应用方案存在几个问题:
- 应用程序和网络协议栈的交互过程中存在用户态和内核态的频繁切换,操作系统在执行此类操作时,会涉及当前进程上下文切换,TLB 也会被频繁更新,导致 MMU 需要经常访问页表,这些都影响数据收发的时延。
- 用户空间缓存和内核空间缓存之间的复制行为,也消耗了大量的时间。
- 另外内核协议栈对数据的各种封包、解包也会消耗 CPU 时钟。
不过技术总在发展,业界专家已经想到了很多新的技术来解决上述问题,这些新技术包括 DPDK、RDMA、XDP 等。
内核旁路技术思想
既然内核是瓶颈所在,明显解决方案就是想办法绕过内核(Kernel-Bypass 技术)
Kernel-Bypass 或者说是内核旁路,主要的思想是:
- 控制层和数据层分离:将数据包处理、内存管理、处理器调度等任务转移到用户空间去完成,而内核仅仅负责部分控制指令的处理。这样就不存在上述所说的系统中断、上下文切换、系统调用、系统调度等等问题。
- 使用多核编程技术代替多线程技术: 并设置 CPU 的亲和性,将线程和 CPU 核进行一比一绑定,减少彼此之间调度切换
- 针对 NUMA 系统:尽量使 CPU 核使用所在 NUMA 节点的内存,避免跨内存访问
- 使用大页内存:代替普通的内存,减少 Cache-Miss
DPDK
数据平面开发工具包 (data plane development kit, DPDK) 是在用户态运行的一组软件库和驱动程序,可在大部分主要的 CPU 体系结构上加速网络数据包的处理。作为 Linux 基金会下的开源项目, DPDK 在推动通用 CPU 在高性能网络环境中发挥了很大的作用。
DPDK 技术概述
传统的网络设备(NIC),在执行底层数据平面功能,比如数据包的转发和路由,使用的都是专用的集成电路芯片(ASIC), 以 ASIC 芯片 + 配套软件的产品架构提供的吞吐量也能达到高性能网络的要求,但其新产品推出收到芯片开发周期的限制,而且 ASIC 供应商之间也不存在软件移植的可能。
后续 Intel、Cavium 等半导体公司开始将通用多核处理器引入网络数据处理领域,进行底层的数据包处理,这些方案再处理器性能和成本方面可以和 ASIC 芯片的网络产品竞争,但问题在于,以 Linux 内核协议栈为基础的网络方案存在许多瓶颈,无法高性能地处理数据包。
此时需要一个解决方案来消除这些瓶颈,同时还要保持原有 Linux 程序的兼容性,新方案最好还要以库的形式打包到 Linux 发行版中,在用户需要时来管理各种网络设备。
这些目标随着 Intel 基于 Nehalem 微架构的 Xeon 处理器推出的 DPDK 而实现,DPDK 绕过(bypass) Linux 内核,在用户态执行数据包处理,以提供尽可能的网络性能。
DPDK 程序运行在操作系统的用户态,利用自带的数据平台库进行数据包的发送、处理和接收、绕过运行在内核态的网络协议栈,大幅提升数据包的处理效率。
DPDK 的网卡驱动程序运行在用户态,屏蔽了网卡硬件发起的大部分中断,采用主动轮询的方式持续检查网卡的接受/发送队列,查看是否有新数据到达或者是否可以继续发送数据,而从实现高吞吐量和低时延,因为 DPDK 的驱动程序 也被称为 轮询模式驱动程序 (poll mode driver)。
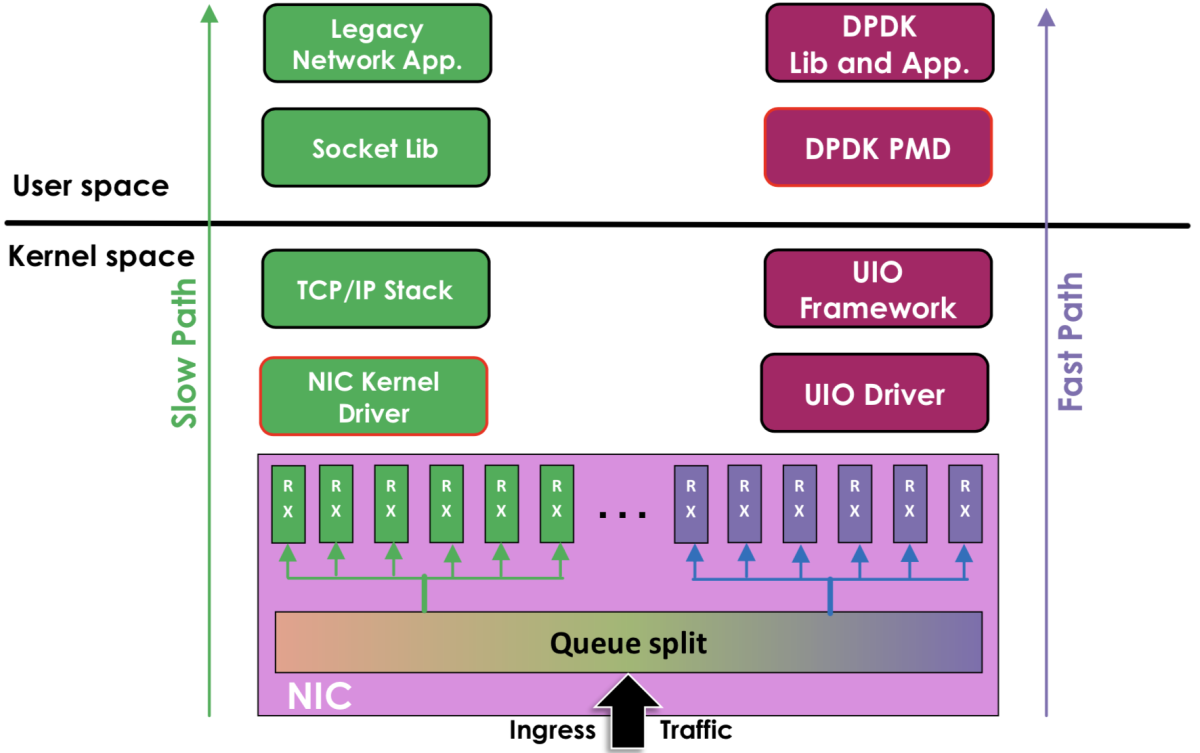
图:DPDK 与 传统内核网络的对比
- 左边是原来的方式数据从 网卡 -> 驱动 -> 协议栈 -> Socket 接口 -> 业务
- 右边是 DPDK 的方式,基于 UIO(Userspace I/O)旁路数据。数据从 网卡 -> DPDK 轮询模式-> DPDK 基础库 -> 业务
不过 Linux 内核 仍然是 DPDK 实现的基础,比如 内核中的 UIO 驱动框架,它为 DPDK 驱动程序 提供获取寄存器的地址、中断计数等功能, 另外 内核提供的大页 机制,也是 DPDK 进行内存管理的基础。
DPDK 性能指标
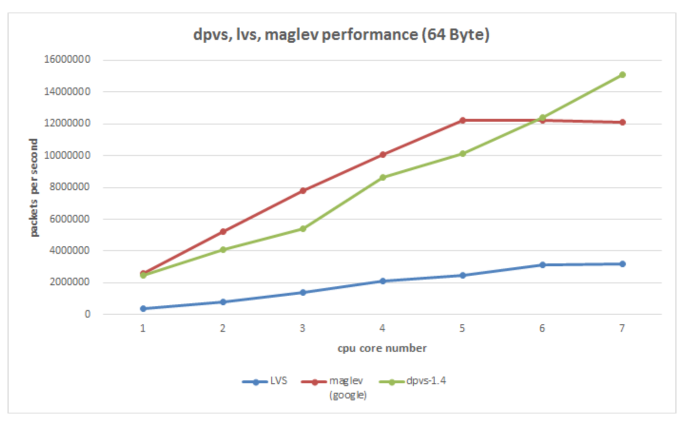
以下为 DPVS (LVS 的 DPDK 优化版本)与 传统 LVS 在 PPS 转发上的指标对比,性能提升约 300%;
内核旁路技术代表
内核旁路有两类的技术代表:
使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包 的处理效率。
使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能
很多企业如 Facebook 的 Katran、美团的 MGW、爱奇艺的 DPVS 等使用 DPDK、ebpf 技术进行 kernel bypass,直接全部在用户态进行流量的处理,也正是基于此,才得以实现单机千万并发的性能指标。