2.3.3 Facebook 故障分析与总结
Facebook “史诗级故障”发生在 2021 年 10 月 4 日,故障绕过了所有的高可用设计,让 Facebook 公司旗下的 Facebook、Instagram、WhatsApp 等众多服务出现了长达 7 个小时宕机。故障的影响范围极广,差点导致严重的二次故障,搞崩半个互联网。
如此大规模服务瘫痪不是 DNS 就是 BGP 出现了问题。这次,Facebook 很倒霉,DNS 和 BGP 一起出现了问题。
图 2-4 Facebook宕机
Facebook 官方发布的故障原因是,运维人员修改 BGP 路由规则时,错误地删除了 Facebook 自治域 AS32934 [1]内的“权威域名服务器”的路由配置!这个操作导致所有 Facebook 域名的解析请求被丢弃,世界各地“DNS 解析器”无法正常解析 Facebook 相关的域名。
1.故障现象
故障期间使用 dig 命令查询 Facebook 域名解析记录,出现 SERVFAIL 错误。
➜ ~ dig @1.1.1.1 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @8.8.8.8 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
根据上一篇内容的介绍,这是“权威解析服务器”出现了问题。那影响范围可就大了,世界上所有的用户都无法再正常打开 Facebook 相关的网站、APP。
用户无法正常登录 APP 时,通常会“疯狂”地发起重试。Facebook 用户太多了,云服务商 Cloudflare 的 DNS 解析器(1.1.1.1)请求瞬间增大了 30 倍。如果 1.1.1.1 宕机,恐怕半个互联网都会受到影响。
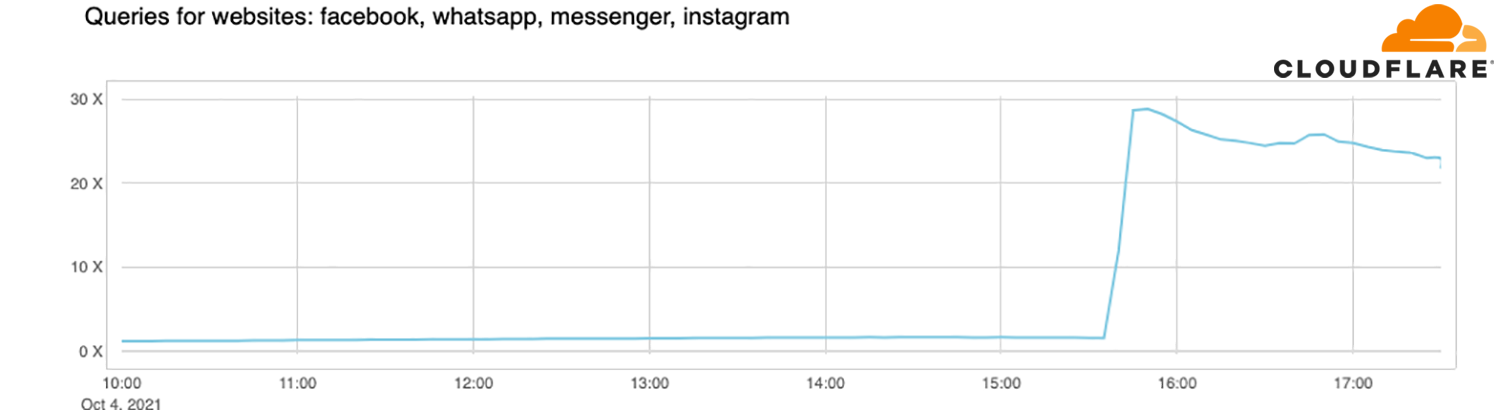
图 2-5 Cloudflare 的域名解析服务器 1.1.1.1 在 Facebook 故障时请求瞬间增大 30 倍
此次故障还影响到 Facebook 内部,员工的工作邮箱、门禁系统统统失效,Facebook 从外到内完全停摆。据 Facebook 员工回忆当天的情形:“ 今天大家都很尴尬,不知道发生了什么,也不知道该做什么,只好假装什么都没有发生”。
故障从美国东部标准时间上午 11 点 51 分开始,最终 6 个小时以后服务恢复。
2.故障总结
此次故障实际上是 Facebook BGP 路由系统和 DNS 系统一系列设计缺陷叠加,而从放大了故障影响:
- 运维人员发布了错误的 BGP 路由公告;
- 恰巧 Facebook 的权威域名服务器的 IP 包含在这部分路由中。
这就导致域名解析请求无法路由到 Facebook 内部网络。
因为是 DNS 出现问题,运维人员也受故障影响,很难再通过远程的方式修复,修复团队只能是紧急跑到数据中心修复(道听途说打了“飞的”过去)。
Facebook 这次故障带给我们以下 DNS 系统的设计思考:
- 部署形式思考:可选择将“权威域名服务器”放在 SLB(Server Load Balancer,负载均衡)后方,或采用 OSPF Anycast [2]的部署形式避免单点问题。
- 部署位置思考:可选择自建集群 + 公有云服务混合部署,利用云增强 DNS 系统可靠性。
如图 2-6 所示,amazon.com 和 facebook.com 的权威域体系对比:amazon.com 的权威解析服务器有多套不同的地址,分散于不同的 TLD 域名服务器,所以它的抗风险能力肯定强于 Facebook。


图 2-6 amazon.com 与 facebook.com 域名系统对比
3.运维操作的警示
部分运维操作具有很大风险,比如更改 BGP 通告、修改路由、修改防火墙策略等。如果操作失误,极可能造成远程连接无法使用。这时候想远程修复就难了,只能接近物理机才能处理。
这对我们的思考是,如果生产环境要进行很大风险性的操作,除了慎之又慎外,应该使用一种二次确认的方式,比如修改 iptables 规则,修改之后引入 10 分钟“观察期”,观察期结束后,系统自动恢复原来的配置。运维人员分析观察期内的数据变化,确认没有任何问题之后,再执行正式操作。
书籍已出版 【在京东购买】
