7.7.1 资源模型与资源管理
理解容器编排调度的基础,首先需要掌握 Kubernetes 的资源管理机制。本节将详细介绍 Kubernetes 的资源模型、资源分配和节点资源管理机制。
1. 资源模型
在 Kubernetes 中,Pod 是最小的调度单元。因此,所有与调度和资源管理相关的属性都应包含在 Pod 对象中。
与调度密切相关的主要是 CPU 和内存的配置,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-5
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr-5
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
像 CPU 这类的资源被称作可压缩资源。这类资源不足时,Pod 内的进程变得卡顿,但 Pod 不会因此被杀掉。
Kubernetes 中的 CPU 资源计量单位为“个数”。例如,CPU=1 表示 Pod 的 CPU 限额为 1 个 CPU。具体的“1 个 CPU”定义取决于宿主机的硬件配置,它可能对应多核处理器中的一个核心、一个超线程(Hyper-Threading)或虚拟机中的一个虚拟处理器(vCPU)。对于不同硬件环境构建的 Kubernetes 集群,1 个 CPU 的实际算力可能有所不同,但 Kubernetes 只保证 Pod 能够使用到“1 个 CPU”这一逻辑单位的算力。
实际上,Kubernetes 中常用的 CPU 计量单位是毫核(Millcores,缩写 m)。1 个 CPU 等于 1000m。这样可以更精确地度量和分配 CPU 资源。例如,分配给某个容器 500m CPU,相当于 0.5 个 CPU。
像内存这样的资源被称作不可压缩资源。这类资源不足时,可能会杀死 Pod 中的进程,甚至驱逐整个 Pod。 对于内存资源来说,最基本的计量单位是字节。如果没有明确指定单位,默认以字节为计量单位。为了方便使用,Kubernetes 支持以 Ki、Mi、Gi、Ti、Pi、Ei 或 K、M、G、T、P、E 为单位来表示内存大小。例如,下面是一些相同内存值的不同表示方式:
128974848, 129e6, 129M, 123Mi
注意区分 Mi 和 M,1Mi=1024x1024,1M=1000x1000。随着数值的增加,Mi 和 M 计算的差异会越来越大,因此使用带小 i 的更准确。
2. 资源分配
Kubernetes 使用以下两个属性来描述 Pod 的资源分配和限制:
- requests:表示容器请求的资源量,Kubernetes 会确保 Pod 获得这些资源。requests 是调度的依据,调度器只有在节点上有足够可用资源时,才会将 Pod 调度到该节点。
- limits:表示容器可使用的资源上限,防止容器过度消耗资源,导致节点过载。limits 会配置到 cgroups 中相应任务的 /sys/fs/cgroup 文件中。
Pod 是由一个或多个容器组成的,因此资源需求是在容器级别进行描述的。如图 7-32 所示,每个容器都可以通过 resources 属性单独设定相应的 requests 和 limits。例如,container-1 指定其容器进程需要 500m(即 0.5 个 CPU)才能被调度,并且允许最多使用 1000m(即 1 个 CPU)。
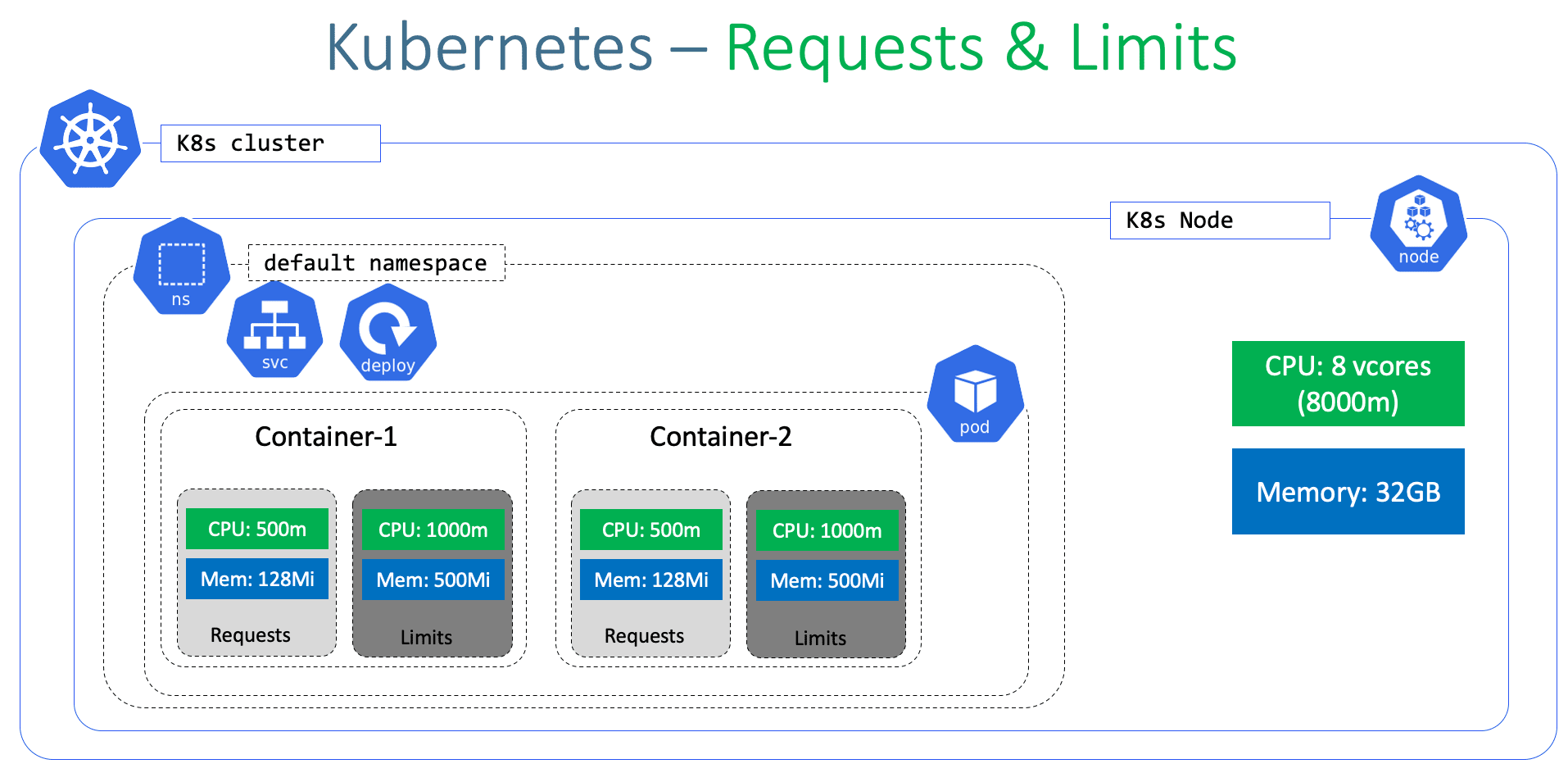
图 7-32 容器的 requests 与 limits 配置
requests 和 limits 除了用于表明资源需求和限制资源使用之外,还有一个隐含功能,它决定了 Pod 的 QoS(Quality of Service,服务质量)等级。
3. 服务质量等级
Kubernetes 根据每个 Pod 中容器资源配置情况,为 Pod 设置不同的服务质量(QoS,Quality of Service)等级。不同的 QoS 等级决定了当节点资源紧张时,Kubernetes 该如何处理节点上的 Pod,也就是接下来要讨论的驱逐(eviction)机制。
图 7-33 展示了 Pod 的 QoS 级别与资源配置之间的对应关系,具体名称及含义如下:
- Guaranteed:Pod 中每个容器必须配置相等的 CPU 和内存 requests 与 limits。此类 Pod 通常用于需要稳定资源的应用(如数据库)。在节点资源紧张时,Guaranteed 类型的 Pod 最不容易被驱逐。
- Burstable:Pod 中至少有一个容器设置了 requests 或 limits,但并非所有容器的请求和限制都相等。Burstable 类型的 Pod 在资源使用上有一定灵活性,但优先级低于 Guaranteed 类型。在节点资源紧张时,可能会被驱逐。
- Best Effort:Pod 中的容器没有设置 CPU 或内存的 requests 和 limits。Best Effort 类型的 Pod 通常用于临时或非关键任务,会尽可能使用可用资源,但在资源紧张时最容易被驱逐。
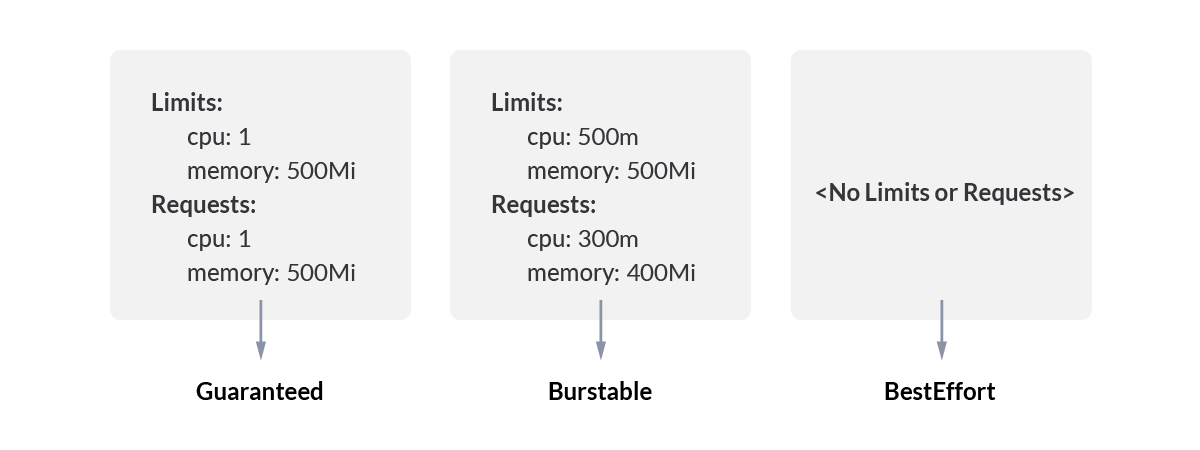
图 7-33 QoS 级别与资源配置对应关系
从上述描述可见,未配置 requests 和 limits 时,Pod 的 QoS 等级最低,在节点资源紧张时最容易受到影响。因此,合理配置 requests 和 limits 参数,能够提高调度精确度,并增强服务的稳定性。
4. 节点资源管理
在 Kubernetes 系统中,每个节点都运行着容器运行时(如 Docker、containerd)以及负责管理容器的组件 kubelet。这些基础服务在节点上运行时,会占用一定的资源。因此,当 Kubernetes 进行资源管理时,必须为这些基础服务预先分配一部分资源。
Kubelet 通过下面两个参数,控制节点上基础服务的资源预留额度:
- --kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi]:预留给 Kubernetes 组件 CPU、内存和存储资源。
- --system-reserved=[cpu=100mi][,][memory=100Mi][,][ephemeral-storage=1Gi]:预留给操作系统的 CPU、内存和存储资源。
需要注意的是,考虑 Kubernetes 驱逐机制,kubelet 会确保节点上的资源使用率不会达到 100%。因此,Pod 实际可用的资源会更少一些。最终,一个节点的资源分配如图 7-34 所示。
Node Allocatable Resource(节点可分配资源)= Node Capacity(节点所有资源) - Kube Reserved(Kubernetes 组件预留资源)- System Reserved(系统预留资源)- Eviction Threshold(为驱逐预留的资源)。

图 7-34 Node 资源分配
5. 驱逐机制
当不可压缩类型的资源(如可用内存 memory.available、宿主机磁盘空间 nodefs.available、镜像存储空间 imagefs.available)不足时,保证节点稳定的手段是驱逐(Eviction)那些不太重要的 Pod,使其能够重新调度到其他节点。
承担上述职责的组件为 kubelet。kubelet 运行在节点上,能够轻松感知节点的资源耗用情况。当 kubelet 发现不可压缩类型的资源即将耗尽时,触发两类驱逐策略。
kubelet 的第一种驱逐策略是软驱逐(soft eviction)。
由于节点资源耗用可能是临时性波动,通常会在几十秒内恢复。因此,当资源耗用达到设定阈值时,应先观察一段时间再决定是否触发驱逐操作。与软驱逐相关的 kubelet 配置参数如下:
- --eviction-soft:软驱逐触发条件。例如,可用内存(memory.available)< 500Mi,可用磁盘空间(nodefs.available)< 10% 等等。
- --eviction-soft-grace-period:软驱逐宽限期。例如,memory.available=2m30s,即可用内存 < 500Mi,并持续 2m30s 后,才真正开始驱逐 Pod。
- --eviction-max-pod-grace-period:Pod 优雅终止宽限期,该参数决定给 Pod 多少时间来优雅地关闭(graceful shutdown)。
kubelet 的第二种驱逐策略是硬驱逐(hard eviction)。
硬驱逐主要关注节点稳定性,防止资源耗尽导致节点不可用。硬驱逐相当直接,当 kubelet 发现节点资源耗用达到硬驱逐阈值时,会立即杀死相应的 Pod。与硬驱逐相关的 kubelet 配置参数仅有 --eviction-hard,其配置方式与 --eviction-soft 一致,笔者就不再赘述了。
需要注意的是,当 kubelet 驱逐部分 Pod 后,节点的资源使用可能在一段时间后再次达到阈值,进而触发新的驱逐,形成循环,这种现象称为“驱逐波动”。为了预防这种情况,kubelet 预留了以下参数:
- --eviction-minimum-reclaim:决定每次驱逐时至少要回收的资源量,以停止驱逐操作;
- --eviction-pressure-transition-period:决定 kubelet 上报节点状态的时间间隔。较短的上报周期可能导致频繁更改节点状态,从而引发驱逐波动。
最后,以下是与驱逐相关的 kubelet 配置示例:
$ kubelet --eviction-soft=memory.available<500Mi,nodefs.available < 10%,nodefs.inodesFree < 5%,imagefs.available < 15% \
--eviction-soft-grace-period=memory.available=1m30s,nodefs.available=1m30s \
--eviction-max-pod-grace-period=120 \
--eviction-hard=memory.available<500Mi,nodefs.available < 5% \
--eviction-pressure-transition-period=30s \
--eviction-minimum-reclaim="memory.available=500Mi,nodefs.available=500Mi,imagefs.available=1Gi"
书籍已出版 【在京东购买】
