3.3.2 数据包过滤工具 iptables
Netfilter 的钩子回调固然强大,但需要通过编写程序才能使用,并不适合系统管理员日常运维。为此,基于 Netfilter 框架开发的应用便出现了,如 iptables。
熟悉 Linux 的工程师通常都接触过 iptables,它常被视为 Linux 内置的防火墙管理工具。严谨地讲,iptables 能做的事情远超防火墙的范畴,它的定位应是能够代替 Netfilter 多数常规功能的 IP 包过滤工具。
1. iptables 表和链
Netfilter 中的钩子在 iptables 中的对应称作“链”(chain)。
iptables 默认包含 5 条规则链 PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING,它们分别对应了 Netfilter 的 5 个钩子。
iptables 将常见的数据包管理操作抽象为具体的规则动作,当数据包在内核协议栈中经过 Netfilter 钩子时(也就是 iptables 的链),iptables 会根据数据包的源/目的 IP 地址、传输层协议(如 TCP、UDP)以及端口等信息进行匹配,并决定是否触发预定义的规则动作。
iptables 常见的动作及含义如下:
- ACCEPT:允许数据包通过,继续执行后续的规则。
- DROP:直接丢弃数据包。
- RETURN:跳出当前规则“链”(Chain,稍后解释),继续执行前一个调用链的后续规则。
- DNAT:修改数据包的目标网络地址。
- SNAT:修改数据包的源网络地址。
- REDIRECT:在本机上做端口映射,比如将 80 端口映射到 8080,访问 80 端口的数据包将会重定向到 8080 端口对应的监听服务。
- REJECT:功能与 DROP 类似,只不过它会通过 ICMP 协议向发送端返回错误信息,比如返回 Destination network unreachable 错误。
- MASQUERADE:地址伪装,可以理解为动态的 SNAT。通过它可以将源地址绑定到某个网卡上,因为这个网卡的 IP 可能是动态变化的,此时用 SNAT 就不好实现;
- LOG:内核对数据包进行日志记录。
在 iptables 规则体系中,不同的链用于处理数据包在协议栈中的不同阶段,将不同类型的动作归类,也更便于管理。如数据包过滤的动作(ACCEPT、DROP、RETURN、REJECT 等)可以合并到一处,数据包的修改动作(DNAT、SNAT)可以合并到另外一处,这便有了规则表的概念。
iptables 共有 5 张规则表,它们的名称与含义如下:
- raw 表:主要用于绕过数据包的连接追踪机制。默认情况下,内核会对数据包进行连接跟踪,而使用 raw 表可以避免 conntrack 处理,从而减少系统开销,提高数据包转发性能。
- mangle 表:用于修改数据包的特定字段,主要应用于数据包头的调整。例如,可以修改 ToS(服务类型)、TTL(生存时间)或 Mark(标记)等字段,以影响 QoS 处理或路由决策。
- nat 表:负责网络地址转换(NAT),用于修改数据包的源地址或目的地址。当数据包进入协议栈时,nat 表中的规则决定是否以及如何进行地址转换,从而影响数据包的路由。例如,可用于访问私有网络或负载均衡。
- filter 表:用于数据包过滤,决定数据包是放行(ACCEPT)、拒绝(REJECT)还是丢弃(DROP)。如果不指定 -t 选项,iptables 默认操作的就是 filter 表。
- security 表:主要用于安全策略强化,通常配合 SELinux 使用,以施加更严格的访问控制策略。除 SELinux 相关应用外,security 表并不常用。
举一个具体的例子。如下命令所示,放行 TCP 22 端口的流量,即在 INPUT 链上添加 ACCEPT 动作。
$ iptables -A INPUT -p tcp --dport 22 -j ACCEPT
将规则表与链进行关联,而不是规则本身与链关联,通过一个中间层解耦了链与具体的某条规则,原本复杂的对应关系就变得简单了。
最后,根据图 3-3 总结数据包进入 iptables 处理流程。首先经过 raw 进行连接跟踪处理,接着 mangle 修改数据包字段,随后 nat 进行地址转换,最后 filter 执行最终的放行或丢弃策略,而 security 仅在 SELinux 环境下应用额外的安全规则。

图 3-3 数据包通过 Netfilter 时的流动过程 图片来源
2. iptables 自定义链与应用
除了 5 个内置链 之外,iptables 还支持管理员创建自定义链。
自定义链 可以看作对调用它的内置链的扩展。当数据包进入自定义链后,可以选择返回调用它的内置链,或继续跳转到其他自定义链,从而实现更复杂的流量处理逻辑。这种机制使 iptables 不仅仅是一个 IP 包过滤工具,还在容器网络等场景中发挥了关键作用。
例如,在 Kubernetes 中,kube-proxy 依赖 iptables 的自定义链 实现 Service 负载均衡,通过规则跳转管理流量转发,从而确保容器服务的高效通信。一旦创建一个 Service,Kubernetes 会在主机添加这样一条 iptable 规则。
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m tcp --dport 80 -j KUBE-SVC-NWV5X
这条 iptables 规则的含义是:凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-NWV5X 的 iptables 链进行处理。10.0.1.175 其实就是 Service 的 VIP(Virtual IP Address,虚拟 IP 地址)。可以看到,它只是 iptables 中一条规则的配置,并没有任何网络设备,所以 ping 不通。
接下来的 KUBE-SVC-NWV5X 是一组规则的集合,如下所示:
-A KUBE-SVC-NWV5X --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2
-A KUBE-SVC-NWV5X --mode random --probability 0.50000000000 -j KUBE-SEP-X3P26
-A KUBE-SVC-NWV5X -j KUBE-SEP-57KPR
可以看到,这一组规则实际上是一组随机模式(–mode random)的自定义链,也是 Service 实现负载均衡的位置。随机转发的目的地为 KUBE-SEP-<hash> 自定义链。
查看自定义链KUBE-SEP-<hash>的明细,我们就很容易理解 Service 进行转发的具体原理了,如下所示:
-A KUBE-SEP-WNBA2 -s 10.244.3.6/32 -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2 -p tcp -m tcp -j DNAT --to-destination 10.244.3.6:9376
可以看到,自定义链 KUBE-SEP-<hash> 是一条 DNAT 规则。DNAT 规则的作用是在 PREROUTING 钩子处,也就是在路由之前,将流入 IP 包的目的地址和端口,改成 –to-destination 所指定的新的目的地址和端口。而目的地址和端口 10.244.3.6:9376,正是 Service 代理 Pod 的 IP 地址和端口。这样,访问 Service VIP 的 IP 包经过上述 iptables 处理之后,就已经变成了访问具体某一个后端 Pod 的 IP 包了。
上述实现负载均衡的方式在 kube-proxy 中被称为 iptables 模式。在该模式下,所有容器间的请求和负载均衡操作 都依赖 iptables 规则 进行处理,因此其性能直接受到 iptables 机制的影响。随着 Service 数量的增加,iptables 规则数量也呈现暴涨趋势,导致系统负担加重。
为解决 iptables 模式的性能问题,kube-proxy 新增了 IPVS 模式。该模式使用 Linux 内核四层负载均衡模块 IPVS 实现容器间请求和负载均衡,性能和 Service 规模无关。
需要注意的是,内核中的 IPVS 模块仅负责负载均衡和代理功能,而 Service 的完整工作流程还依赖 iptables 进行初始流量捕获和过滤。不过,这些 iptables 规则仅用于辅助,其数量相对有限,不会随着 Service 数量增加而指数级膨胀。
如图 3-4 所示,展示了 iptables 与 IPVS 两种模式在性能方面的对比。可以观察到,当 Kubernetes 集群 中的 Service 数量达到 1,000 个(对应约 10,000 个 Pod)时,两者的性能表现开始出现明显差异。
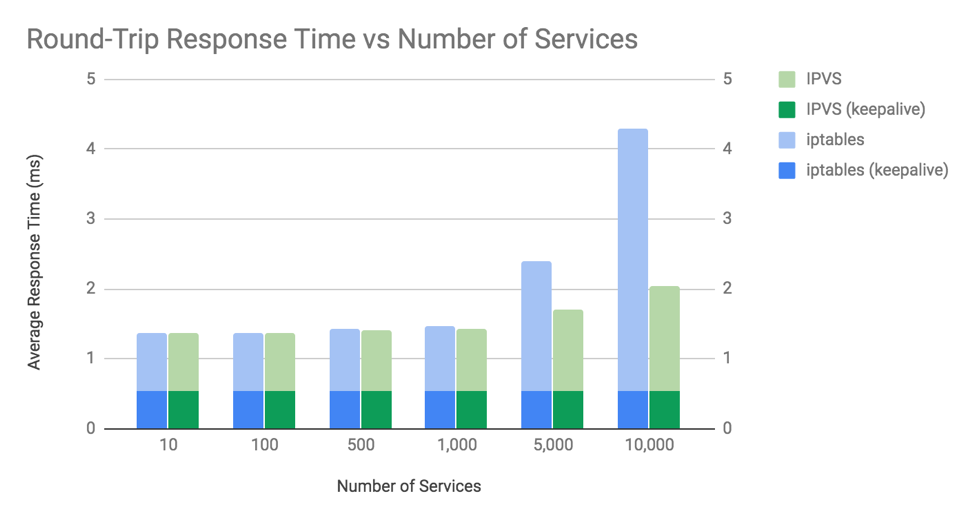
图 3-4 iptables 与 IPVS 的性能差异(结果越低,性能越好)图片来源
现在,你应该理解了,当 Kubernetes 集群规模较大时,应尽量避免使用 iptables 模式,以避免性能瓶颈。如果使用的是 Cilium 作为容器间通信解决方案,还可以构建无需 kube-proxy 组件的 Kubernetes 集群,利用笔者稍后介绍的“内核旁路”技术绕过 iptables 限制,全方位提升容器网络性能。
书籍已出版 【在京东购买】
