7.4 容器运行时与 CRI 接口
Docker 在诞生十多年后,未曾料到仍会重新成为舆论焦点。事件的起因是 Kubernetes 宣布将进入废弃 dockershim 支持的倒计时,随后讹传讹被人误以为 Docker 不能再用了。
虽说此次事件有众多标题党的推波助澜,但也从侧面说明了 Kubernetes 与 Docker 的关系十分微妙。本节,我们把握这两者关系的变化,从中理解 Kubernetes 容器运行时接口的演变。
7.4.1 Docker 与 Kubernetes
由于 Docker 太流行了,Kubernetes 没有考虑支持其他容器引擎的可能性,完全依赖并绑定于 Docker。那时,Kubernetes 通过内部的 DockerManager 组件调用 Docker API 来创建和管理容器。

图 7-12 Kubernetes 通过内部的 DockerManager 组件管理容器
随着市场上出现越来越多的容器运行时,比如 CoreOS 推出的开源容器引擎 Rocket(简称 rkt),Kubernetes 在 rkt 发布后采用类似强绑定 Docker 的方式,添加了对 rkt 的支持。随着容器技术的快速发展,如果继续采用与 Docker 类似的强绑定方式,Kubernetes 的维护工作将变得无比庞大。
Kubernetes 需要重新审视与各种容器运行时的适配问题了。
7.4.2 容器运行时接口 CRI
从 Kubernetes 1.5 版本开始,Kubernetes 在遵循 OCI 标准的基础上,将容器管理操作抽象为一系列接口。这些接口作为 Kubelet(Kubernetes 节点代理)与容器运行时之间的桥梁,使 Kubelet 能通过发送接口请求来管理容器。
管理容器的接口称为“CRI 接口”(Container Runtime Interface,容器运行时接口)。如下面的代码所示,CRI 接口其实是一套通过 Protocol Buffer 定义的 API。
// https://github.com/kubernetes/cri-api/blob/master/pkg/apis/services.go
// RuntimeService 定义了管理容器的 API
service RuntimeService {
// CreateContainer 在指定的 PodSandbox 中创建一个新的容器
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
// StartContainer 启动容器
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
// StopContainer 停止正在运行的容器。
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
...
}
// ImageService 定义了管理镜像的 API。
service ImageService {
// ListImages 列出现有的镜像。
rpc ListImages(ListImagesRequest) returns (ListImagesResponse) {}
// PullImage 使用认证配置拉取镜像。
rpc PullImage(PullImageRequest) returns (PullImageResponse) {}
// RemoveImage 删除镜像。
rpc RemoveImage(RemoveImageRequest) returns (RemoveImageResponse) {}
...
}
根据图 7-13,CRI 的实现由三个主要组件协作完成:gRPC Client、gRPC Server 和具体的容器运行时。具体来说:
- Kubelet 充当 gRPC Client,调用 CRI 接口;
- CRI shim 作为 gRPC Server,响应 CRI 请求,并将其转换为具体的容器运行时管理操作。
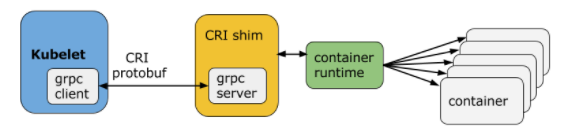
图 7-13 CRI 的工作原理
由此,市场上的各类容器运行时,只需按照规范实现 CRI 接口,就可以无缝接入 Kubernetes 生态。
7.4.3 Kubernetes 专用容器运行时
2017 年,Google、RedHat、Intel、SUSE 和 IBM 一众大厂联合发布了 CRI-O(Container Runtime Interface Orchestrator)项目。从名称可以看出,CRI-O 的目标是兼容 CRI 和 OCI,使 Kubernetes 能在不依赖传统容器引擎(如 Docker)的情况下,仍能有效管理容器。

图 7-14 Kubernetes 专用的轻量运行时 CRI-O
Google 推出 CRI-O 的意图明显,即削弱 Docker 在容器编排领域的主导地位。但彼时 Docker 在容器生态中的市场份额仍占绝对优势。对于普通用户而言,如果没有明确的收益,并没么动力把 Docker 换成别的容器引擎。
不过,我们也可以想象,Docker 当时的内心一定充满了被抛弃的焦虑。
7.4.4 Containerd 与 CRI
Docker 并没有“坐以待毙”,开始主动进行革新。回顾本书第一章 1.5.1 节关于 Docker 演进的内容,Docker 从 1.1 版本起开始重构,并拆分出了 Containerd。
早期,Containerd 单独开源,并未捐赠给 CNCF,还适配了其他容器编排系统,如 Swarm,因此并未直接实现 CRI 接口。出于诸多原因的考虑,Docker 对外部开放的接口也依然保持不变。在这种背景下,Kubernetes 中出现了两种调用链(如图 7-15 所示):
- 通过适配器 dockershim 调用:首先 dockershim 调用 Docker,然后 Docker 调用 Containerd,最后 Containerd 操作容器;;
- 通过适配器 CRI-containerd 调用:首先 CRI-containerd 调用 Containerd,随后 Containerd 操作容器。

图 7-15 早期的 Containerd 和 Docker,都不支持直接与 CRI 交互
在这一阶段,Kubelet 和 dockershim 的代码都托管在同一个仓库中,意味着 dockershim 由 Kubernetes 负责组织、开发和维护。因此,每当 Docker 发布新版本时,Kubernetes 必须集中精力快速更新 dockershim。此外,Docker 作为容器运行时显得过于庞大。Kubernetes 弃用 dockershim 有了充分的理由和动力。
再来看 Docker。2018 年,Docker 将 Containerd 捐赠给 CNCF,并在 CNCF 的支持下发布了 1.1 版。与 1.0 版相比,1.1 版的最大变化在于完全支持 CRI 标准,这意味着原本作为 CRI 适配器的 CRI-Containerd 也不再需要。
Kubernetes v1.24 版本正式移除 dockershim,实质上是废弃了内置的 dockershim 功能,转而直接对接 Containerd。此时,再观察 Kubernetes 与容器运行时之间的调用链,你会发现,与 DockerShim 和 CRI-containerd 的交互相比,调用步骤最多减少了两步:
- 用户只需抛弃 Docker 的情怀,容器编排至少可以省略一次调用,获得性能上的收益;
- 对 Kubernetes 而言,选择 Containerd 作为容器运行时,调用链更短、更稳定、占用的资源更少。
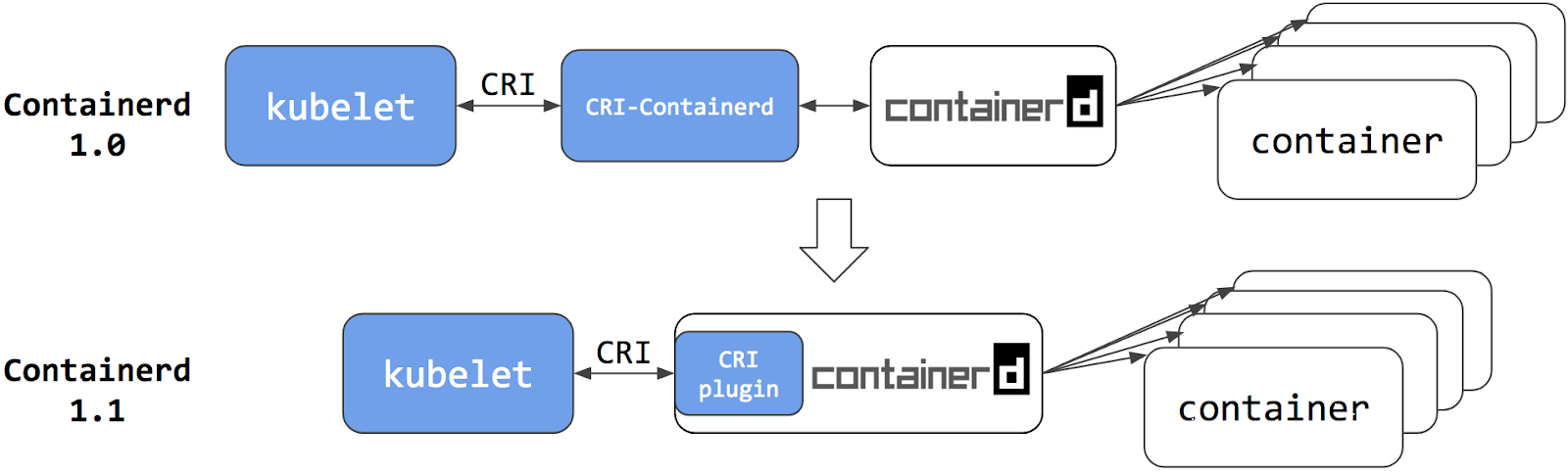
图 7-16 Containerd 1.1 起,开始完美支持 CRI
根据 Kubernetes 官方提供的性能测试数据[1],Containerd 1.1 相比 Docker 18.03,Pod 的启动延迟降低了 20%、CPU 使用率降低了 68%、内存使用率降低了 12%。这是一个相当显著的性能改善。

图 7-17 Containerd 与 Docker 的性能对比
7.4.5 安全容器运行时
事实上,虽然容器提供一个与系统中的其它进程资源相隔离的执行环境,但是与宿主机系统是共享内核的。如果有一个容器进程被恶意程序攻击,就有可能造成容器逃逸,轻则破坏当前的容器,重则造成 Linux 内核崩溃,导致整个机器宕机。
为了提高安全性,很多运维人员会将容器“嵌套”在虚拟机中,将容器与同一主机上的其他进程完全隔离。但在虚拟机中运行容器会丧失容器的速度和敏捷性优势。为了解决这个问题,Intel 和 Hyper.sh(现为蚂蚁集团的一部分)在 2016 年,几乎同时发布了各自的解决方案,分别是 Intel Clear Containers 和 runV 项目。
2017 年,Intel 和 Hyper.sh 两家公司将各自的项目合并,互补优势,创建了开源项目 Kata Containers。该项目的原理如图 7-18 所示,本质上是通过硬件虚拟化技术(如 QEMU/KVM)为每个容器/Pod 分配独立的内核,将其运行在一个精简的轻量级虚拟机中。因此,它“像容器一样敏捷,像虚机一样安全”(The speed of containers, the security of VMs)。

图 7-18 Kata Containers 与传统容器对比 图片来源
为了与上层容器编排系统对接,Kata Containers 会启动一个进程(shimv2)来负责容器的生命周期管理。shimv2 相当于 Kata Containers 与容器运行时之间的兼容层,支持标准的容器接口,如 CRI(容器运行时接口)或 Docker API。这使得容器编排系统能够像操作普通容器一样管理容器,而不需要意识到容器实际上是运行在一个虚拟机中。

图 7-19 Kubernetes 通过 CRI 接口管理 Kata Containers 容器 图片来源
除了 Kata Containers,2018 年底,AWS 发布了安全容器项目 Firecracker。其核心是一个用 Rust 编写的虚拟化管理器,利用 Linux 内核虚拟机(KVM)来创建和运行轻量级虚拟机。不难看出,无论是 Kata Containers 还是 Firecracker,它们实现安全容器的方法殊途同归,都是为每个进程分配独立的操作系统内核,从而有效防止容器进程“逃逸”或夺取宿主机控制权的问题。
7.4.6 容器运行时生态
如图 7-20 所示,目前已有十几种容器运行时实现了 CRI 接口,具体选择哪一种取决于 Kubernetes 安装时宿主机的容器运行时环境。但对于云计算厂商而言,除非出于安全性需要(如必须实现内核级别的隔离),大多数情况都会选择 Containerd 作为容器运行时。毕竟对于它们而言,性能与稳定才是核心的生产力与竞争力。

图 7-20 容器运行时生态 图片来源
参见 https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/ ↩︎
书籍已出版 【在京东购买】
