9.3.1 指标的处理
提到指标,就不得不提 Prometheus 系统。Prometheus 是继 Kubernetes 之后,云原生计算基金会(CNCF)的第二个正式项目。该项目发展至今,已成为云原生系统中处理指标监控的事实标准。
额外知识
有趣的是,像 Kubernetes 一样,Prometheus 也源自 Google 的 Borg 体系,其原型是与 Borg 同期诞生的内部监控系统 BorgMon。Prometheus 的发起原因与 Kubernetes 类似,都是希望以更好的方式将 Google 内部系统的设计理念传递给外部开发者。
作为监控系统,Prometheus 的基本原理如图 9-3 所示,通过 pull(拉取)方式收集被监控对象的指标数据,并将其存储在 TSDB(时序数据库)中。其他组件(如 Grafana 和 Alertmanager)配合这一机制,实现指标数据可视化和预警功能。
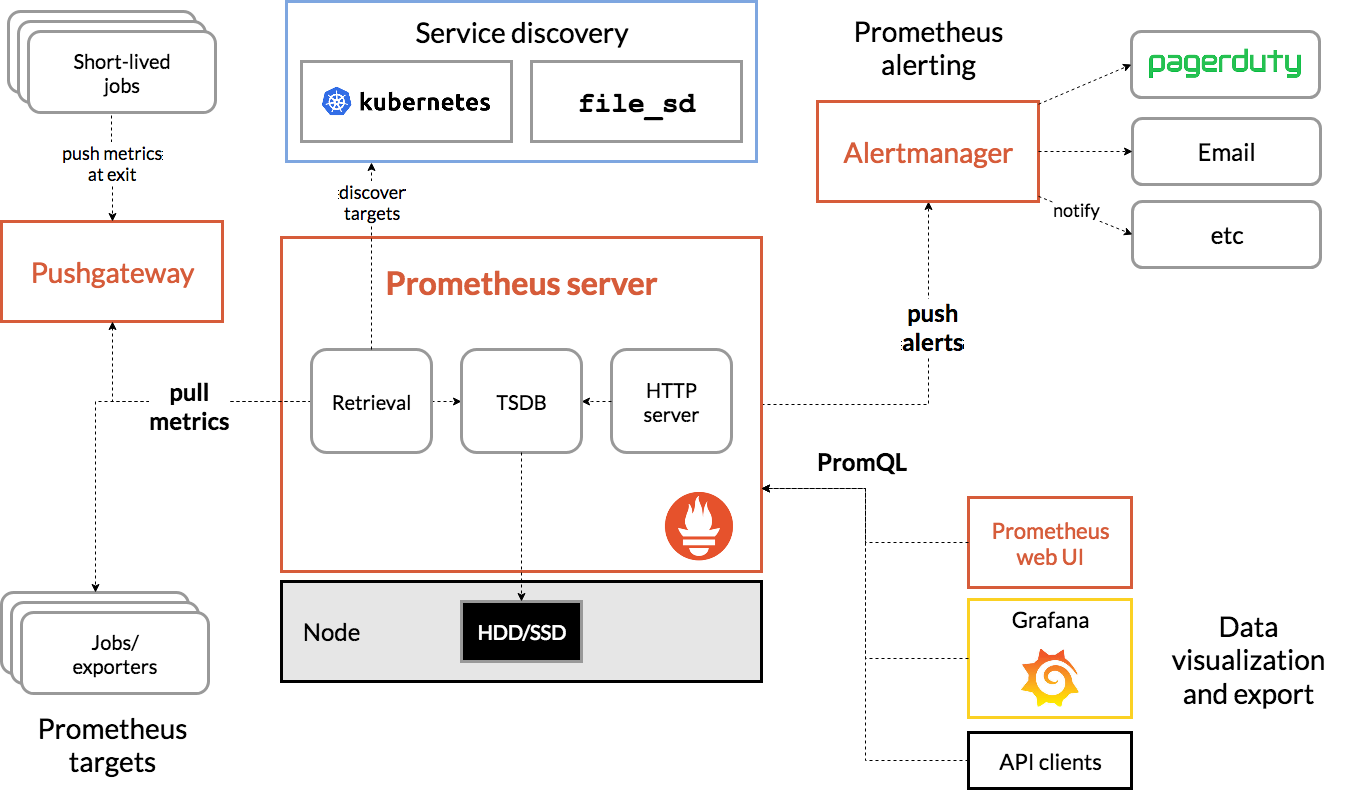
图 9-3 Prometheus 的工作原理
1. 定义指标的类型
为便于理解和使用不同类型的指标,Prometheus 定义了四种指标类型:
- 计数器(Counter):一种只增不减的指标类型,用于记录特定事件的发生次数。常用于统计请求次数、任务完成数量、错误发生次数等。在监控 Web 服务器时,可以使用 Counter 来记录 HTTP 请求的总数,通过观察这个指标的增长趋势,能了解系统的负载情况;
- 仪表盘(Gauge):一种可以任意变化的指标,用于表示某个时刻的瞬时值。常用于监控系统的当前状态,如内存使用量、CPU 利用率、当前在线用户数等;
- 直方图(Histogram):用于统计数据在不同区间的分布情况。它会将数据划分到多个预定义的桶(bucket)中,记录每个桶内数据的数量。常用于分析请求延迟、响应时间、数据大小等分布情况。比如监控服务响应时间时,Histogram 可以将响应时间划分到不同的桶中,如 0-100ms、100-200ms 等,通过观察各个桶中的数据分布,能快速定位响应时间的集中区间和异常情况;
- 摘要(Summary):和直方图类似,摘要也是用于统计数据的分布情况,但与直方图不同的是,Summary 不能提供数据在各个具体区间的详细分布情况,更侧重于单一实例(例如单个服务实例)的数据进行计算。

图 9-4 Prometheus 的四种指标类型
2. 使用 Exporter 收集指标
收集指标看似简单,但实际上复杂得多:首先,应用程序、操作系统和硬件设备的指标获取方式各不相同;其次,它们通常不会以 Prometheus 格式直接暴露。例如:
- Linux 的许多指标信息存储在 /proc 目录下,如 /proc/meminfo 提供内存信息,/proc/stat 提供 CPU 信息;
- Redis 的监控数据通过执行 INFO 命令获取;
- 路由器等硬件设备的监控数据通常通过 SNMP 协议获取。
为了解决上述问题,Prometheus 设计了 Exporter 作为监控系统与被监控目标之间的“中介”,负责将不同来源的监控数据转换为 Prometheus 支持的格式。
Exporter 可以作为独立服务运行,也可以与应用程序共享同一进程,只需集成 Prometheus 客户端库即可。Exporter 通过 HTTP 协议返回符合 Prometheus 格式的文本数据,Prometheus 服务端会定期拉取这些数据。以下是一个 Exporter 示例,它返回名为 http_request_total 的 Counter 类型指标。
$ curl http://127.0.0.1:8080/metrics | grep http_request_total
# HELP http_request_total The total number of processed http requests
# TYPE http_request_total counter // 指标类型 类型为 Counter
http_request_total 5
得益于 Prometheus 良好的社区生态,现在已有大量用于不同场景的 Exporter,涵盖了基础设施、中间件和网络等各个领域。如表 9-1 所示,这些 Exporter 扩展了 Prometheus 的监控范围,几乎覆盖了用户关心的所有监控目标。
表 9-1 常用的 Exporter
| 范围 | 常用 Exporter |
|---|---|
| 数据库 | MySQL Exporter、Redis Exporter、MongoDB Exporter、MSSQL Exporter 等 |
| 硬件 | Apcupsd Exporter、IoT Edison Exporter、IPMI Exporter、Node Exporter 等 |
| 消息队列 | Beanstalkd Exporter、Kafka Exporter、NSQ Exporter、RabbitMQ Exporter 等 |
| 存储 | Ceph Exporter、Gluster Exporter、HDFS Exporter、ScaleIO Exporter 等 |
| HTTP 服务 | Apache Exporter、HAProxy Exporter、Nginx Exporter 等 |
| API 服务 | AWS ECS Exporter、Docker Cloud Exporter、Docker Hub Exporter、GitHub Exporter 等 |
| 日志 | Fluentd Exporter、Grok Exporter 等 |
| 监控系统 | Collectd Exporter、Graphite Exporter、InfluxDB Exporter、Nagios Exporter、SNMP Exporter 等 |
| 其它 | Blockbox Exporter、JIRA Exporter、Jenkins Exporter、Confluence Exporter 等 |
3. 使用时序数据库存储指标
存储数据本来是一项常规操作,但当面对存储指标类型的场景来说,必须换一种思路应对。
举一个例子,假设你负责管理一个小型集群,该集群有 10 个节点,运行着 30 个微服务系统。每个节点需要采集 CPU、内存、磁盘和网络等资源使用情况,而每个服务则需要采集业务相关和中间件相关的指标。假设这些加起来一共有 20 个指标,且按每 5 秒采集一次。那么,一天的数据规模将是:
10(节点)* 30(服务)* 20 (指标) * (86400/5) (秒) = 103,680,000(记录)
对于一个仅有 10 个节点的小规模业务来说,7*24 小时不间断生成的数据可能超过上亿条记录,占用 TB 级别的存储空间。虽然传统数据库也可以处理时序数据,但它们并未充分利用时序数据的特点。因此,使用这些数据库往往需要不断增加计算和存储资源,导致系统的运维成本急剧上升。
通过下面的例子,我们来分析指标数据的特征。可以发现,指标数据是纯数字型的、具有时间属性、旨在揭示某些事件的趋势和规律,它们不涉及关系嵌套、主键/外键,也不需要考虑事务处理。
{
"metric": "http_requests_total", // 指标名称,表示 HTTP 请求的总数
"labels": { // 标签,用于描述该指标的不同维度
"method": "GET", // HTTP 请求方法
"handler": "/api/v1/users", // 请求的处理端点
"status": "200", // HTTP 响应状态码
},
"value": 1458, // 该维度下的请求数量
},
针对时序数据特点,业界已发展出专门优化的数据库类型 —— 时序数据库(Time-Series Database,简称 TSDB)。与常规数据库(如关系型数据库或 NoSQL 数据库)相比,时序数据库在设计和用途上存在显著差异,比如:
- 数据结构: 时序数据库一般采用 LSM-Tree,这是一种专为写密集型场景设计的存储结构,其原理是将数据先写入内存,待积累一定量后批量合并并写入磁盘。因此,时序数据库在写入吞吐量方面,通常优于常规数据库(基于 B+Tree);
- 数据保留策略:时序数据具有明确的生命周期(监控数据只需要保留几天)。为防止存储空间无限膨胀,时序数据库通常支持自动化的数据保留策略。比如设置基于时间的保留规则,超过 7 天就会自动删除。
Prometheus 服务端内置了强大的时序数据库(与 Prometheus 同名),“强大”并非空洞的描述,它在 DB-Engines 排行榜中常年稳居前三[1]。该数据库提供了专为时序数据设计的查询语言 PromQL(Prometheus Query Language),可轻松实现指标的查询、聚合、过滤和计算等操作。掌握 PromQL 语法是指标可视化和告警处理的基础,笔者就不再详细介绍其语法细节了,具体可以参考 Prometheus 文档。
4. 指标的图形化和预警
采集和存储指标的最终目的是分析数据的趋势变化,预测业务需求(图形化),以及持续监控数据波动变化,及时发现问题(预警)。
Prometheus 提供了基本的展示功能,但其图形界面相对简单,许多用户会将 Prometheus 与 Grafana 配合使用(这也是 Prometheus 官方推荐的组合方案)。图 9-5 展示了一个 Grafana 仪表板(Dashboard)。将指标数据可视化,能够更方便地从中发现规律。例如,趋势分析可以帮助判断服务 QPS 的增长趋势,从而预测何时需要扩容;对照分析则能对比新旧版本的 CPU、内存等资源消耗,评估性能差异;在故障分析方面,服务性能的波动、瓶颈或潜在问题也更加容易识别。

图 9-5 Grafana 的仪表盘
除了图形化展示外,指标的另一个主要用途是预警。例如,当某个服务的 QPS 超过设定的阈值时,系统自动发送一封邮件通知工程师及时处理,这就是一种预警。Prometheus 提供了专门的 Alertmanager 组件,用来管理和通知 Prometheus 生成的预警信息。
如下面的例子所示,Prometheus 根据预设的条件定期检查数据,一旦满足预警条件,Prometheus 触发预警并将其发送到 Alertmanager。
// 定期使用 PromQL 语法检查过去 5 分钟内,某个被监控目标(instance)中指定服务(job)的 QPS 是否超过 1000。
groups:
- name: example-alerts
rules:
- alert: HighQPS
expr: sum(rate(http_requests_total[5m])) by (instance, job) > 1000
for: 5m
labels:
severity: critical
annotations:
summary: "High QPS detected on instance {{ $labels.instance }}"
description: "Instance {{ $labels.instance }} (job {{ $labels.job }}) has had a QPS greater than 1000 for more than 5 minutes."
Alertmanager 接收到预警后,根据配置对预警进行分组(将相似标签的预警合并)、抑制(防止预警风暴发生)、静默(在维护期间,屏蔽预警)和路由(发送到短信、邮件、微信)处理。
https://db-engines.com/en/ranking/time+series+dbms ↩︎
书籍已出版 【在京东购买】
