6.3.3 Multi Paxos
既然 Paxos Basic 可以确定一个值,想确定多个值那就运行多次 Paxos Basic —— 这就是 Multi Paxos 。
来看一个具体的例子,当 S1 收到客户端的请求 jmp(提案)时(假设此时是 S3 宕机),运行多次 Paxos Basic 会出现什么情况:
- 第一轮 Paxos Basic:尝试在索引 4 处写入提案(cmp),但 Prepare 阶段发现 S2 的索引 3 已经存在 sub 提案,S1 的索引 4 处,写入提案(sub)。
- 第二轮 Paxos Basic:S1 继续尝试下一个日志索引 5,本轮就S1、S2 的索引 5 的提案达成共识;
- 此外,上述过程中还发现 S2 存在空洞日志。S1 发起新一轮 Paxos Basic,S2 的索引 3 处,cmp 提案达成共识。
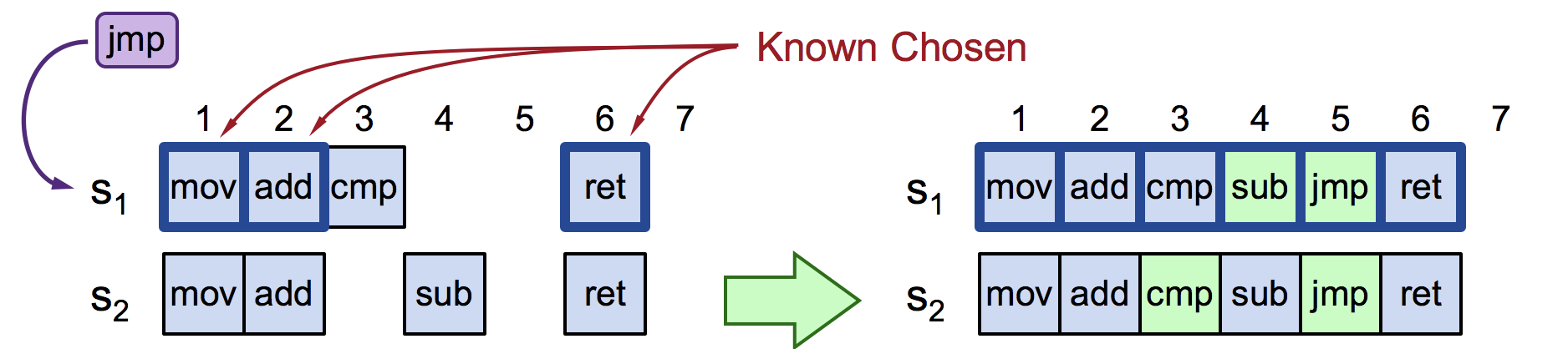
图 6-14 当节点收到客户端的请求命令 jmp(提案)时情况
决议jump 提案时经历了 3 轮 Basic Paxos,花费 6 个 RTT(日志顺序不一致,以及 Basic Paxos 本身就需要 2 个 RTT)。此外,当多个节点同时发起提案时,还导致频繁出现活锁。
形成活锁的原因是 Paxos 算法中“节点众生平等”,每个节点都可以并行的发起提案。如何不破坏 Paxos 的“节点众生平等”基本原则,又能在提案节点中实现主次之分,限制每个节点都有不受控的提案权利?这是共识算法从理论研究走向实际工程的第一步; 如何就多个值形成决议,并在过程成解决网络通信效率问题?,这是共识算法走向实际工程的第二步;解决了上述两个问题,并在过程中保证安全性。就认为是一个可“落地”的共识系统。
Multi Paxos 算法对此的改进是增加“选主”机制。节点之间就要维持 T 间隔的心跳,如果一个节点在 2T 时间内没收到“提案节点”的心跳,那该节点通过 Basic Paxos 中的准备阶段、批准阶段,向其他节点广播“我希望成为提案节点”,如果得到决策节点的多数派批准,则宣告竞选成功。选主成功后,“提案节点”处理所有的客户端请求,其他节点如果收到客户端的请求,要么丢弃要么将请求重定向到 Leader 节点。
一旦选举出多数节点接受的领导者。那领导者就可以跳过 Basix Paxos 中 Prepare 多数派承诺阶段,直接向其他节点广播 Accept 消息即可。这样一个提案达成共识,只需要一轮 RPC。
不过呢,Lamport 的论文主要关注的是 Basic Paxos 的算法基础和正确性证明,虽然在 Basic Paxos 之上做了 Multi Paxos 扩展,但没有深入描述如何通过领导者角色解决多轮提案的效率问题,且没有给出充分的优化细节。2014 年,斯坦福的学者 Diego Ongaro 和 John Ousterhout 发表了论文《In Search of an Understandable Consensus Algorithm》,提出了 Multi-Paxos 思想上简化和改进的 Raft 算法,明确提出了“选主”、“日志复制”等概念以及实现细节的描述。该论文斩获 USENIX ATC 2014 大会 Best Paper 荣誉,Raft 算法更是成为 etcd、Consul 等分布式系统的实现基础。