7.5 资源与调度
对于 Kubernetes 这个编排系统而言,编排调度的首要职责是实现资源提供者(Node)、资源使用者(Pod)两者之间最恰当的撮合。想要实现这个目标,那么管理以及分配集群节点的资源,至少要清楚这么几个问题:
- 资源模型的抽象有哪些种类的资源,如何表示这些资源。
- 资源的调度如何描述一个 workload 的资源申请、如何描述一台 node 当前的资源分配状态,例如已分配/未分配资源量。
- 资源的限额如何确保 workload 使用的资源量不超出预设范围、如何确保 workload 和系统/基础服务的限额,使二者互不影响。
资源模型的抽象
与调度关系最密切的物理资源是处理器和内存/显存,根据调度的处理方式的差别,这两类资源又可分为可压缩和不可压缩两类。
可压缩的资源典型的是 CPU,此类资源超限时,容器进程使用 CPU 会被限制,应用表现变得卡顿,业务延迟明显增加,但容器进程不会被杀掉。在 Kubernetes 中,一个 Node 节点 CPU 核心数量乘以 1000,得到的就是该 Node 节点总的 CPU 总数量。CPU 的计量单位为毫核(m),计量方式有多种写法:50m、0.5(1000m*0.5)。CPU 的计量是绝对值,这意味着无论容器运行在单核、双核机器上,500m CPU 表示的是相同的计算能力。
不可压缩的资源为内存、显存(GPU),容器之间无法共享且完全独占,这也就意味着资源一旦耗尽或者不足,容器进程一定产生 OOM 问题(Out of Memory,内存溢出)并被杀掉。内存的计算单位为字节,计量方式有多种写法,譬如使用 M(Megabyte)、Mi(Mebibyte)以及不带单位的数字,以下表达式所代表的是相同的值。
128974848, 129e6, 129M, 123Mi
注意 Mebibyte 和 Megabyte 的区分,123 Mi = 123*1024*1024B 、123 M = 1*1000*1000 B。1M < 1Mi,显然使用带小 i 的更准确。
由于每台 node 上会运行 kubelet/docker/containerd 等 Kubernetes 相关基础服务,因此并不是一台 node 的所有资源都能给 Kubernetes 创建 pod 用。 所以,Kubernetes 在资源管理和调度时,需要把这些基础服务的资源使用量和 enforcement 单独拎出来。
为此,Kubernetes 提出了 Node Allocatable Resources 提案。
- SystemReserved:操作系统的基础服务,例如 systemd、journald 等,Kubernetes 不能管理这些资源的分配,但是能管理这些资源的限额。
- KubeReserved:预留 Kubernetes 基础设施服务,包括 kubelet/docker/containerd 等等使用的资源。
- Allocatable:可供 Kubernetes 创建 pod 使用的资源
资源申请及限制
Kubernetes 抽象了两个概念用来描述容器资源的分配。
- requests 容器需要的最小资源量。举例来讲,对于一个 Spring Boot 业务容器,这里的 requests 必须是容器镜像中 JVM 虚拟机需要占用的最少资源。
- limits 容器最大可以消耗的资源上限,防止过量消耗资源导致资源短缺甚至宕机。
Pod 是由一到多个容器组成,所以资源的需求作用在容器上的。如下图所示,每一个容器都可以独立地通过 resources 属性设定相应的 requests 和 limits,
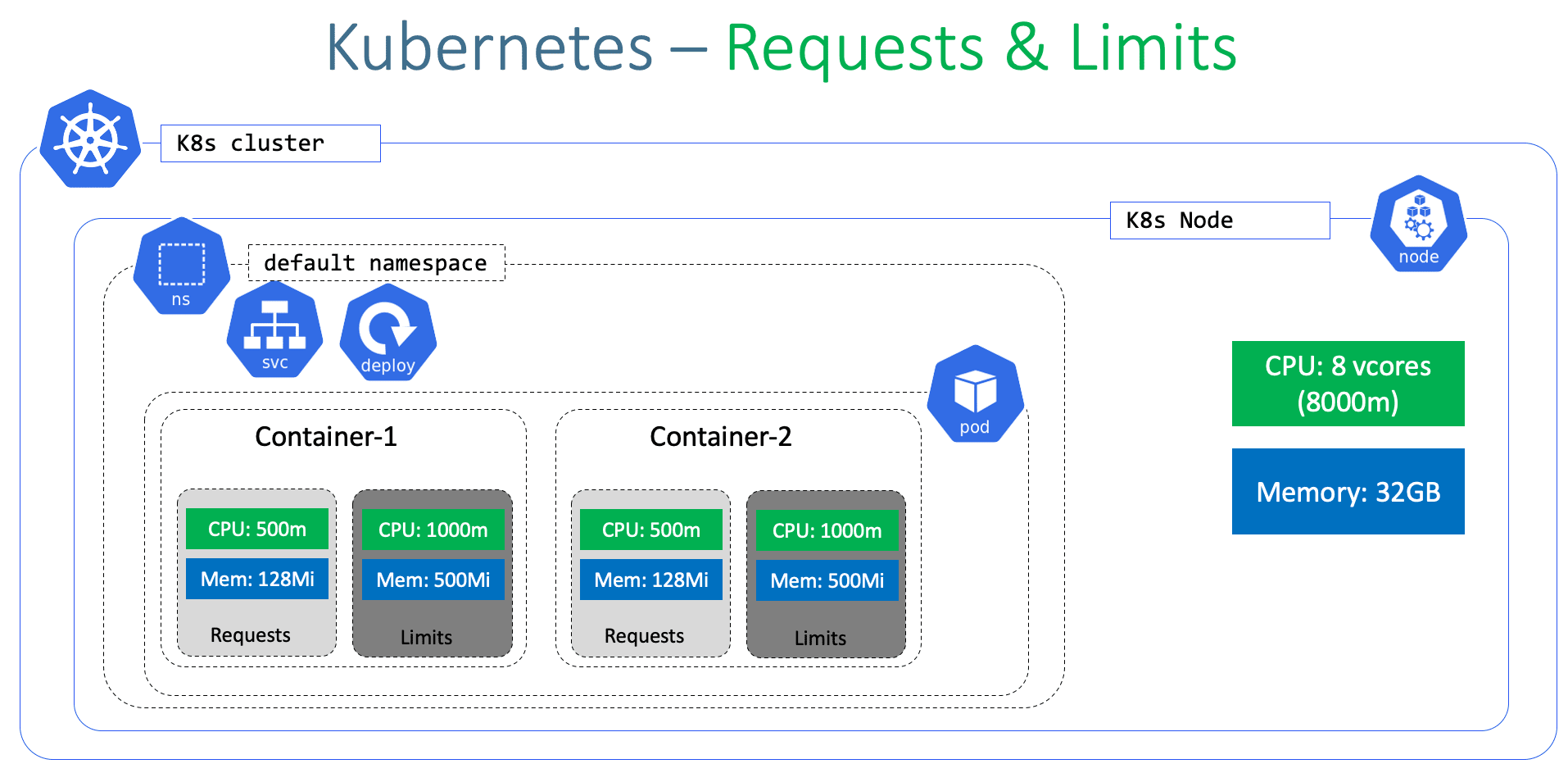
笔者举例子说明容器的资源限制设定。如下代码所示,该资源对象指定容器进程需要 50/1000 核(5%)才能被调度,并且允许最多使用 100/1000 核(10%)。
container:
resources:
requests:
cpu: 50m
memory: 50Mi
limits:
cpu: 100m
memory: 100Mi
容器的资源调度以 requests 为准。有的 Pod 内部进程在初始化启动时会提前开辟出一段内存空间。比如 JVM 虚拟机在启动的时候会申请一段内存空间,如果内存 requests 指定的数值小于 JVM 虚拟机向系统申请的内存,导致内存申请失败( oom-kill ),从而 Pod 出现不断地失败重启。
服务质量 Qos 等级
kubernetes 根据 Pod 内容器内 requests、limits 的设置定义了几类不同的 Pod QoS 级别。在一个超用 (Over Committed,容器 limits 总和大于系统容量上限)系统中,由于容器负载波动会导致操作系统资源不足,最终可能导致部分容器被杀掉。QoS 级别决定了 kubernetes 处理这些 pod 的方式
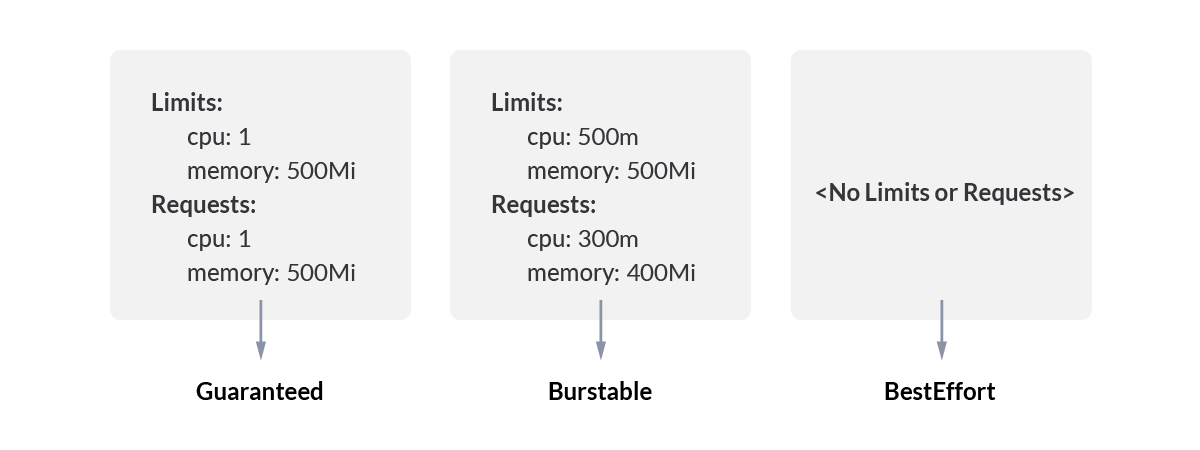
K8s 将容器划分为 3 个 Qos 等级,这种优先级依次递减。
| QoS 级别 | QoS 介绍 |
|---|---|
| Guaranteed | Pod 中的每个容器,包含初始化容器,必须指定内存和 CPU 的 requests 和 limits,并且两者要相等 |
| Burstable | Pod 不符合 Guaranteed QoS 类的标准;Pod 中至少一个容器具有内存或 CPU requests |
| BestEffort | Pod 中的容器没有设置内存和 CPU requests 或 limits |
以内存资源为例,当 Node 节点上内存资源不足时:
- QoS 级别是 BestEffort 的 Pod 最先被 kill 掉。
- 如果 BestEffort 级别的 Pod 已经被 kill 掉了,则继续查找 Burstable 级别的 Pod kill 掉。
- 如果 BestEffort 和 Burstable 的 Pod 都已经被 kill 掉,那么继续查找 Guaranteed 的 Pod,并且这些 pod 使用的内存已经超出了 limits 限制,这些被找到的 pod 会被 kill 掉
集群的稳定性直接决定了其上运行的业务应用的稳定性。而临时性的资源短缺往往是导致集群不稳定的主要因素。
那么如何提高集群的稳定性呢?一方面,可以通过编辑 Kubelet 配置文件来预留一部分系统资源,从而保证当可用计算资源较少时 kubelet 所在节点的稳定性。 这在处理如内存和硬盘之类的不可压缩资源时尤为重要。另一方面,通过合理地设置 pod 的 QoS 可以进一步提高集群稳定性:不同 QoS 的 Pod 具有不同的 OOM 分数,当出现资源不足时,集群会优先 Kill 掉 Best-Effort 类型的 Pod ,其次是 Burstable 类型的 Pod ,最后是 Guaranteed 类型的 Pod 。